ORStereo: Occlusion-Aware Recurrent Stereo Matching for 4K-Resolution Images
Overview
Stereo reconstruction models trained on small images do not generalize well to high-resolution data. Training a model on high-resolution image size faces difficulties of data availability and is often infeasible due to limited computing resources. In this work, we present the Occlusion-aware Recurrent binocular Stereo matching (ORStereo), which deals with these issues by only training on available low disparity range stereo images. ORStereo generalizes to unseen high-resolution images with large disparity ranges by formulating the task as residual updates and refinements of an initial prediction. ORStereo is trained on images with disparity ranges limited to 256 pixels, yet it can operate 4K-resolution input with over 1000 disparities using limited GPU memory. We test the model’s capability on both synthetic and real-world high-resolution images. Experimental results demonstrate that ORStereo achieves comparable performance on 4K-resolution images compared to state-of-the-art methods trained on large disparity ranges. Compared to other methods that are only trained on low-resolution images, our method is 70% more accurate on 4K-resolution images.
4K-resolution stereo dataset
We collected a set of 4K-resolution stereo images for evaluating ORStereo’s performance on high-resolution data. These images and ground truth data will be made publicly available. The images are collected in various simulated environments rendered by the Unreal Engine and the AirSim plugin. 100 pairs of photo-realistic stereo images from 7 indoor and outdoor scenes are collected. We set up a virtual stereo camera with a baseline of 0.38m. In 3 of the 7 scenes, the cameras have a horizontal viewing angle of 46 degrees. For the remaining 4 scenes, the horizontal viewing angle is 60 degrees. The image size of the virtual camera is 4112x3008 pixels. These camera parameters are selected to match the real-world sensor that we are using for data collection. The AirSim plugin provides us with a depth image for every captured RGB image. We compute the true disparities and occlusion masks from the depth images.

The following figure shows another pair of the collected stereo images in detail. Note that all disparities and occlusion masks are associated with the left image.

Access the 4K-resolution dataset
All of the stereo images, together with the true disparity and occlusion mask are available here.
Concerning the large file size of a 4K-resolution floating point image, we save the disparity as compressed PNG files in RGBA format. We provide a simple Python funcion to read the floating point disparity back from those PNG files. Access the code here.
More results
Results on the Scene Flow dataset
When trained on the Scene Flow dastaset only, ORStereo achieves similar EPE value (0.74) among the state-of-the-art models trained with low-resolution data.
| MCUA1 | Bi3D2 | GwcNet3 | FADNet4 | GA-Net5 |
|---|---|---|---|---|
| 0.56 | 0.73 | 0.77 | 0.83 | 0.84 |
| WaveletStereo6 | DeepPruner7 | SSPCV-Net8 | AANet9 | ORStereo (ours) |
|---|---|---|---|---|
| 0.84 | 0.86 | 0.87 | 0.87 | 0.74 |
When working on low-resolution inputs such as the Scene Flow dataset, ORStereo only goes through the first phase. Two sample results are shown as follows.
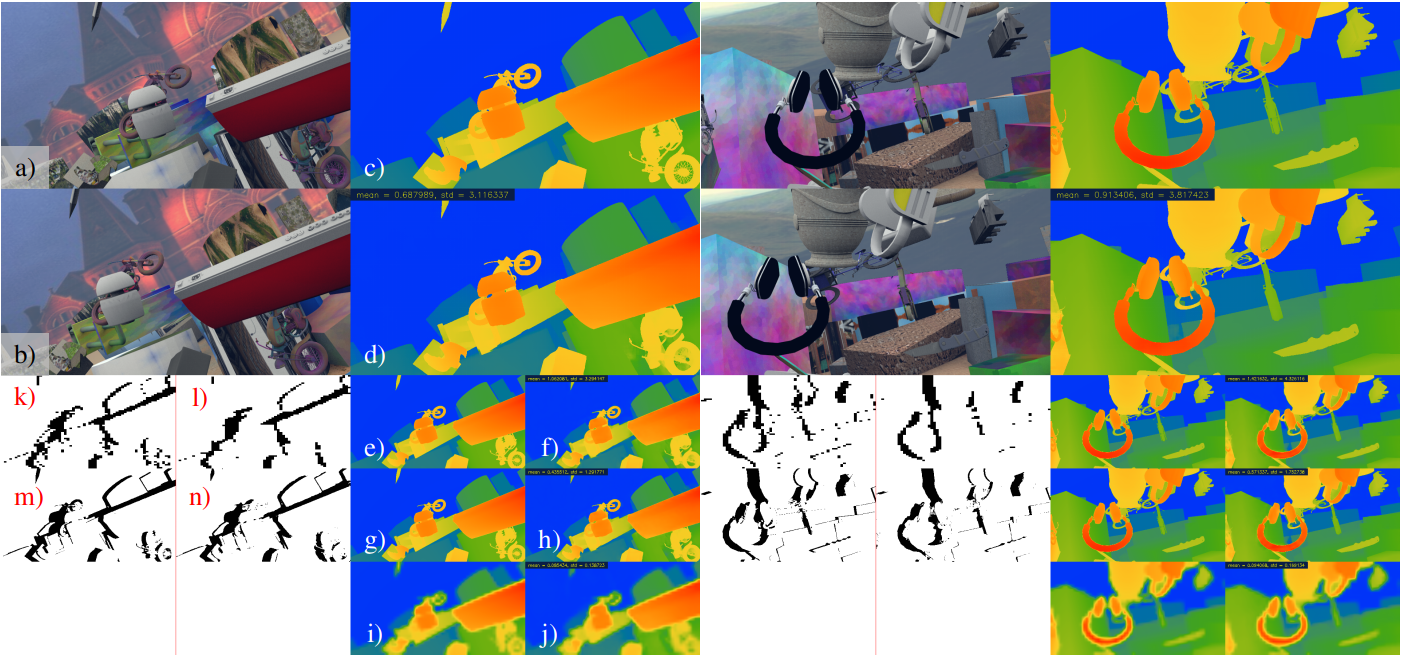
In the previous image:
- a, b) Left and right images.
- c, d) True disparity and prediction after NLR.
- e, f) True disparity and prediction before NLR.
- g, h) True disparity and prediction by RRU.
- i, j) True disparity and prediction by BDE.
- k, l) True occlusion and prediction by BME.
- m, n) True occlusion and prediction by RRU.
- The numbers on the predicted disparities are the EPE and standard deviation.
- The true and predicted disparity values are all scaled according to the sizes of the feature levels. E.g., g) has a magnitude 1/2 of e) or c). The full-resolution versions of this figure can be found here.
Results on the Middlebury dataset
ORStereo acheives better accuracy on full resolution benchmark than the state-of-the-art models that trained on low-resolution data. Note that HSM is trained on high-resolution data.
| Model & scale | AANet9 1/2 | DeepPruner7 1/4 | SGBMP10 full | ORStereo (ours) full | HSM11 full |
|---|---|---|---|---|---|
| EPE | 6.37 | 4.80 | 7.58 | 3.23 | 2.07 |
We have submitted our results to the Middlebury evaluation page. Check out our results under the name ORStereo.
Results on 4K-resolution stereo images
ORStereo achieves the best EPE among all the related state-of-the-art models including the HSM, which is a model trained on high-resolution data.
| Model | Scale | Range | EPE | GPU Memory (MB) |
|---|---|---|---|---|
| AANet9 | 1/8 | 192 | 9.96 | 8366 |
| DeepPruner7 | 1/8 | 192 | 8.31 | 4196 |
| SGBMP10 | 1 | 256 | 4.21 | 3386 |
| ORStereo (ours) | 1 | 256 | 2.37 | 2059 |
| HSM11 | 1/2 | 768 | 2.41 | 3405 |
The following figures are the sample cases shown in the submitted paper.
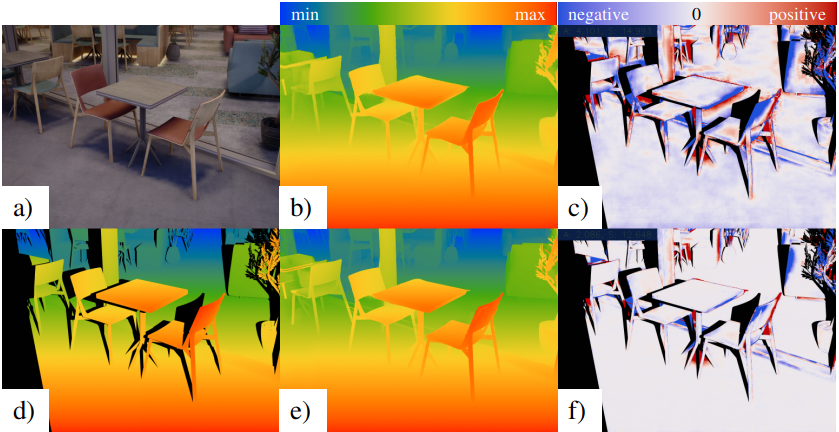

The full resolution version of the previous two figures are available here.
Manuscript
Please refer to this arXiv link.
@misc{hu2021orstereo,
title={ORStereo: Occlusion-Aware Recurrent Stereo Matching for 4K-Resolution Images},
author={Yaoyu Hu and Wenshan Wang and Huai Yu and Weikun Zhen and Sebastian Scherer},
year={2021},
eprint={2103.07798},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Contact
- Yaoyu Hu: yaoyuh@andrew.cmu.edu
- Sebastian Scherer: (basti [at] cmu [dot] edu)
Acknowledgments
This work was supported by Shimizu Corporation.
References
-
Nie, Guang-Yu, Ming-Ming Cheng, Yun Liu, Zhengfa Liang, Deng-Ping Fan, Yue Liu, and Yongtian Wang. “Multi-level context ultra-aggregation for stereo matching.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3283-3291. 2019. ↩
-
Badki, Abhishek, Alejandro Troccoli, Kihwan Kim, Jan Kautz, Pradeep Sen, and Orazio Gallo. “Bi3d: Stereo depth estimation via binary classifications.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1600-1608. 2020. ↩
-
Guo, Xiaoyang, Kai Yang, Wukui Yang, Xiaogang Wang, and Hongsheng Li. “Group-wise correlation stereo network.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3273-3282. 2019. ↩
-
Wang, Qiang, Shaohuai Shi, Shizhen Zheng, Kaiyong Zhao, and Xiaowen Chu. “FADNet: A Fast and Accurate Network for Disparity Estimation.” In 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 101-107. IEEE, 2020. ↩
-
Zhang, Feihu, Victor Prisacariu, Ruigang Yang, and Philip HS Torr. “Ga-net: Guided aggregation net for end-to-end stereo matching.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 185-194. 2019. ↩
-
Yang, Menglong, Fangrui Wu, and Wei Li. “Waveletstereo: Learning wavelet coefficients of disparity map in stereo matching.” In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12885-12894. 2020. ↩
-
Duggal, Shivam, Shenlong Wang, Wei-Chiu Ma, Rui Hu, and Raquel Urtasun. “Deeppruner: Learning efficient stereo matching via differentiable patchmatch.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4384-4393. 2019. ↩ ↩2 ↩3
-
Wu, Zhenyao, Xinyi Wu, Xiaoping Zhang, Song Wang, and Lili Ju. “Semantic stereo matching with pyramid cost volumes.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7484-7493. 2019. ↩
-
Xu, Haofei, and Juyong Zhang. “Aanet: Adaptive aggregation network for efficient stereo matching.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1959-1968. 2020. ↩ ↩2 ↩3
-
Hu, Yaoyu, Weikun Zhen, and Sebastian Scherer. “Deep-learning assisted high-resolution binocular stereo depth reconstruction.” In 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 8637-8643. IEEE, 2020. ↩ ↩2
-
Yang, Gengshan, Joshua Manela, Michael Happold, and Deva Ramanan. “Hierarchical deep stereo matching on high-resolution images.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5515-5524. 2019. ↩ ↩2