GridMap: A simple 2D continuous maze environment for reinforcement learning training
GridMap: A simple 2D continuous maze environment for reinforcement learning training
This is hosted on my github page.
Introduction
GridMap is a simple 2D environment in which the user could build a maze for training reinforcement learning models. Although there is a ‘Grid’ built in the naming, GridMap is designed to work in a continuous coordinate space.
In GridMap, a map is defined in a rectangular 2D plane with its boundaries as the map borders. Obstacles are specified by indexing and created as “blocks”. A starting block and an ending block could also be defined. There is an agent in the GridMap observing its continuous coordinate. The agent could make movement in the map without going into the obstacles and out of any boundaries. The agent starts its journey from the starting block and its task is finding the ending block.
The user could specify reward values for the following cases:
- Agent ends up in a normal grid.
- Agent goes out of boundary but blocked by the border.
- Agent goes into an obstacle but blocked by the obstacle.
- Agent goes back to the starting block.
- Agent goes into the ending block or arrives at a point that is in a circle pre-defined around the ending block.
GridMap uses JSON files to save the environments along with the state-action pairs of the agent. The user could render the map and state-action history into a figure.
This simple 2D environment is used by the authors to prove their concepts in the research related to deep reinforcement learning.
Install
python setup.py install --record files.txt
Currently, to uninstall, the user has to use the recorded file list stored in files.txt during the installation.
cat files.txt | xargs rm -rf
Simple classes.
GridMap defines some simple basic classes to work with.
Class BlockCoor
Represents a 2D coordinate (x, y).
Class BlockCoorDelta
Represents a change of 2D coordinates (dx, dy).
Class BlockIndex
Represents an index of a block (row, col).
Class Block
Represents a Block in GridMap. Block is further inherited to NormalBlock, ObstacleBlock, StartingBlock, and EndingBlock. A Block posses a value property as its ‘value’ for an agent ending up inside its border.
Class GridMap2D
Represents the map with all kinds of blocks.
Class GridMapEnv
Represents a GridMap environment which contains a map. GridMapEnv provides the user with the reset(), step(), and render() interfaces similar to those defined by the gym package.
Class GME_NP
A helper class designed for reinforcement learning training.
Create a map
A map with all grids as the NormalBlocks is created by defining an object of GridMap2D. The user has to specify the row and column numbers of the map, the grid size (stepSize) of the map. Optionally, a name of the map and the value of out-of-boundary could be set as well.
After object creation, the initialize() method should be explicitly called to initialize the map.
Then the user could add obstacles by add_obstacle() member function and set the starting and ending blocks by using set_starting_block() and set_ending_block() functions.
GridMap2D provides various member functions to get access to the internal settings, like setting the values for different block types.
Create an environment
Once we have a GridMap2D object as a map, to create an environment, it could be as simple as referring to this map. When creating a GridMapEnv object, the user could set the name of the environment and set the working directory at the same time.
In our reinforcement learning study, it is required that the interactions between the environment and the reinforcement learning algorithm are carried out through NumPy objects. To do this, we provide an interfacing class, GME_NP defined in EnvInterfaces.py file. There are no major differences between the creation of a GridMapEnv object and a GME_NP object.
Saving and loading environments
The user could use the member functions save() and load() to write or read back an environment and its associated map to or from the file system. When using save() the writing destination will be the location defined by the working directory. However, for load(), the user has to specify the filename of the environment as well as the directory where the file resides.
Similar to GridMap2D objects, an environment is saved as a JSON file. The user is welcome to take a look at it and see various settings GridMapEnv provides.
Interact with the environment
Interactions with a GridMapEnv object or a GME_NP object happen mainly through the following interface functions.
-
reset(): Resets the environment, places the agent back to the starting block defined by the map. Clean the state-action history and the accumulated rewards from the environment. The initial state will be returned. -
step(): Make a single interaction, moving in a specific direction with a certain length of ‘step’, we define this as an ‘action’. By default, the length of action is not limited, however, the resultant of the action will be determined by the boundaries and the obstacles of the map. The rules of actions are listed later in this section.step()returns four objects, namely the new state, the value/reward, the termination flag, and a fourth object that is for the compatibility with other system and not used currently. The user should check the termination flag every time he/she calledstep(). Callingstep()with the environment being in the termination state will cause an exception to be raised. To restart, usereset(). -
render(): Drawn the map with all the state-action pairs happened up to the current time. This function is currently a naive implementation ans has potentially poor performance in terms of graphics. Call this function at the beginning of the training to observe the map and call this function at the end of the training to see the state-action history. The user is encouraged to callfinalize()if a call torender()is made before usingreset()to start a new interaction session/episode.
There are other interface functions that a user could use to interact with the environment or configure different settings.
Basic interaction
As mentioned earlier, interactions are mainly taken out by using reset() to initialize, several step() to make actions and collect rewards, and some calls to render() to visually see the map and the interaction history.
By issuing step(), the user is moving the agent around in the map. reset() always place the agent at the center of the starting block. Each time the user calls step(), an action defined as BlockCoorDelta should be supplied. The environment determines the resultant state, the 2D coordinate, of the agent based on the current state and the action the user chooses to take. The following rules are applied:
The agent tries to move in the direction defined by the action,
-
If the agent goes out of any boundaries of the map before it reaches the destination, it stops at the boundary along its way. The agent receives a reward/penalty from the environment (configured as a property of the map, the value for being out of boundary).
-
If the agent is at a boundary and the action makes it try to go further into the outer region of the map, the agent would not move at all and will receive a reward/penalty from the environment as being out of the boundary.
-
If the agent chooses to stay at a boundary, it receives the same reward/penalty as being out of boundary.
-
If the agent goes across an obstacle as directed by the action, it stops at the grid lines of the obstacle along its way. The agent receives a reward/penalty from the environment defined by the obstacle block the agent is hitting on.
-
If the agent is at a grid line of an obstacle and it tries to go across the obstacle, it will not move at all and will receive a reward/penalty from the environment as being hitting an obstacle.
-
If the agent stays at the grid line of an obstacle, it is the same as hitting the obstacle.
-
If the agent moves to the destination (not an ending block) defined by the action and does not go out of boundary or go into any obstacles, the environment gives it a reward/penalty defined by this
NormalBlcok. -
If the agent makes to the ending block before going out of boundary or hitting any obstacles during the current interaction, the agent receives a reward and the current session terminates. A termination flag is set. Any further call to
step()result in raising an exception. Userender()to see the result andreset()to start over.
Since we are in a continuous space, there are some special cases:
-
If the agent tries to move along a boundary, this is treated as going out of boundary. The agent will not move at all and will receive a reward/penalty from the environment.
-
If the agent tries to move along a grid line of an obstacle, this is treated as hitting the obstacle. The agent will not move at all and will receive a reward/penalty from the environment.
-
If the agent goes across the ending block, it is not considered as a termination. No reward will be given regarding the crossing over the ending block. The reward/penalty is determined by the actual ending position.
-
If the agent goes across the ending block and goes out of the boundary neighboring the ending block. The agent will stop at the boundary. This is not considered as being inside the ending block. It is considered as being out of boundary and the agent receives the reward/penalty of being out of boundary.
-
If the agent goes across the ending block and hits an obstacle neighboring the ending block. The agent will stop at the grid line of the obstacle. This is not considered as being inside the ending block. It is considered as being hitting the obstacle and the agent receives the reward/penalty of hitting that obstacle.
-
If the agent stops right at the grid line of the ending block, it is not considered as reaching the ending block. The reward/penalty is determined by a normal block or by an obstacle or as being out-of-boundary depending on the type of the neighboring block.
-
If the agent lands at the intersection point of two or three obstacles, it will receive rewards/penalties from all the obstacles.
-
If the agent lands at the intersection point of a boundary and an obstacle, it will receive both rewards/penalties for being out of boundary and hitting an obstacle at the same time.
Settings
-
GridMap2D.set_value_normal_block(): Set the reward/penalty for ending up in a normal block. Call this function beforeGridMap2D.initialize(). -
GridMap2D.set_value_obstacle_block(): Set the reward/penalty for hitting an obstacle. Call this function beforeGridMap2D.initialize(). -
GridMap2D.set_value_starting_block(): Set the reward/penalty for returning into the starting block. Call this function beforeGridMap2D.initialize(). -
GridMap2D.set_value_ending_block(): Set the reward for reaching the ending block. Call this function beforeGridMap2D.initialize(). -
GridMap2D.set_value_out_of_boundary(): Set the penalty for being out of the boundary. Call this function beforeGridMap2D.initialize(). -
GridMap2D.set_starting_block(): Set the index of the starting block. Original starting block will be automatically deleted. If the target index is already assigned to an ending block, an exception will be raised. Call this function afterGridMap2D.initialize(). -
GridMap2D.set_ending_block(): Set the index of the ending block. Original ending block will be automatically deleted. If the target index is already assigned to a starting block, an exception will be raised. Call this function afterGridMap2D.initialize(). -
GridMap2D.add_obstacle(): Add an obstacle into the map. If the target index is a starting or ending block, an exception will be raised. Call this function afterGridMap2D.initialize(). -
GridMap2D.random_starting_block(): Randomize the index of the starting block. Original staring block will be automatically deleted. The new starting block will not overwrite any existing ending block or obstacle. Call this function afterGridMap2D.initialize(). -
GridMap2D.random_ending_block(): Randomize the index of the ending block. Original ending block will be automatically deleted. The new ending block will not overwrite any existing starting block or obstacle. Call this function afterGridMap2D.initialize(). -
GridMapEnv.set_working_dir(): Configure the working direcotry of the environment. -
GridMapEnv.set_max_steps(): Set the maximumn interactions allowed for a single epsiode. -
GridMapEnv.enable_nondimensional_step(): Switch to non-dimensional step mode. Usedisable_nondimensional_step()to turn it off. -
GridMapEnv.enable_action_clipping(): Set the minimum and maximum step length. The upper and lower clipping bounds will be used according to the mode of step (dimensional or non-dimensional). Usedisable_action_clipping()to turn it off. -
GridMapEnv.enable_normalized_coordinate(): If this function is called, the state value returned bystep()function will be normalized to [0, 1], with 0 being the smallest coordinate and 1 the maximumn. Usedisable_normalized_coordinate()to turn it off. -
GridMapEnv.enable_random_coordinating(): If this function is called, random noise will be added to the action. The random noise is expressed by a zero-mean Gaussian distribution and the user has to specify the standard variance by calling this function. The random noise will be added to be proportional to the magnitude of the action the agent is trying to take, not based on the actual action length performed by the environment taking consideration of the boundaries and obstacles along the path. Usedisable_random_coordinating()to turn it off. -
GridMapEnv.enable_action_value(): A special per-action penalty is added to the reward/penalty value returned bystep(). This per-action value is used for the purpose of the authors’ research. The user could modify its definition in the code ofstep(). Currently, this per-action penalty is defined based on non-dimensional action and expressed as
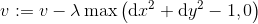
where v is the value, \lambda is a factor. This per-action value penalizes any attempt to make an action with a magnitude over 1.
-
GridMapEnv.random_starting_and_ending_blocks(): Randomize the starting and ending blocks of the associated map. -
GridMapEnv.enable_force_pause(): Call this function to tell the environment to ignore thepauseargument ofrender()and pause with a specific time supplied here byenable_force_pause(). Usedisable_force_pause()to turn it off. -
GME_NP.enable_stuck_check(): MakeGME_NPenvironment to check if the agent gets stuck to a single position. The user could supply a maximum number of stuck actions and a penalty value for reaching this number. If the stuck check is enabled and an agent reaches the maximum allowed stuck number at a specific position, the environment will terminate. Stuck check does not sum stuck counts for different positions. It counts the times the agent is being continuously stuck at the same place. Usedisable_stuck_check()to turn it off.
Replay a state-action history
After interacting with the environment by a sequence of step() calls, the user could issue a render(pause, flagSave, fn) to replay the state-action history up to the current step. When calling render(), the user could define a pause time (decimal number in seconds) and a filename. If a pause time is defined as larger than zero, the rendered figure will pause for that time and then disappear. If a non-positive value is specified as the pause time, the rendered figure will not be closed and the user could use the Q key on the keyboard to close the figure. When a filename is supplied, the rendered figure will be saved as an image. The user should only specify the filename without any preceding paths. The actual storing directory is specified as the Render subdirectory under the working directory.
To save the rendered figure as an image, the user has to explicitly specify True for the argument flagSave of the render() function. The user could choose to omit the fn argument and only set the flagSave argument. This results in writing a rendered image with a composed filename. The file name is defined as “Environment name_action counts-maximum allowed steps_total reward value.png”.
Sample code.
By running the tests, there will be maps and environments generated and saved. The user could exam the test codes and taking them as examples.
Sample map and environment JSON files.
Here is a sample map with 10x10 grids. The starting block index is (2, 2) and the ending block index is (8, 8), both are using zero-based index numbers. There is a line of 6 obstacles. Note that stepSize is not the step size for an agent. It is for defining the actual size of the map. This map is visualized as the following image.
{
"cols": 11,
"endingBlockIdx": [ 8, 8 ],
"endingPoint": [ 8.5, 8.5 ],
"haveEndingBlock": true,
"haveStartingBlock": true,
"name": "S0202_E0808",
"obstacleIndices": [
[ 5, 2 ],
[ 5, 3 ],
[ 5, 4 ],
[ 5, 5 ],
[ 5, 6 ],
[ 5, 7 ],
[ 5, 8 ]
],
"origin": [ 0, 0 ],
"outOfBoundValue": -10,
"rows": 11,
"startingBlockIdx": [ 2, 2 ],
"startingPoint": [ 2.5, 2.5 ],
"stepSize": [ 1, 1 ],
"valueEndingBlock": 100,
"valueNormalBlock": -0.1,
"valueObstacleBlock": -10,
"valueStartingBlock": -0.1
}
A grid map ↑
By referring to the above map, we define a sample environment. Here actStepSize is the non-dimensional step size, which is the actual step size on the map.
-
This environment enables the non-dimensional step by setting
nondimensionalSteptotrue. The value ofactStepSizeis calculated as the product between the actual map length and the value ofnondimensionalStepRatio. Here the map is of length 11 on both sides,nondimensionalStepRatiois 0.1, so step size 1.0 under a non-dimensional step setting is actually 1.1 on the actual map. actionValueFactoris the \lambda for the per-action penalty. Per-action penalty is enabled byflagActionValue.agentActssaves the actions the agent was trying to take. It should be a list of two-element lists, similar toagentLocs.flagActionClipis false, so settingactionCliphas no effects.- Random coordinating is enabled by
isRandomCoordinatingand the standard variance is set to berandomCoordinatingVariance. - Enable normalized coordinate by setting
normalizedCoordinatetotrue.
Other entries are self-explainable
agentCurrentAct: The current action the agent is trying to take.agentCurrentLoc: Current location (coordinate) of the agent.isTerminated:trueif the environment has terminated due to 1) the agent reaches the ending block, 2) maximum steps is reached.mapFn: The filename of the map JSON file.maxSteps: The maximum steps allowed for a single episode.nSteps: Number of steps already taken in the current episode.name: The name of the environment.totalValue: The total reward value the agent has collected up to now.visAgentRadius: The circle radius of the agent on the rendered image.visForcePauseTime: The pause time of theenable_force_pause()function.visIsForcePause: Equivalent to callingenable_force_pause().visPathArrowWidth: Actions of an agent will be represented as arrows. This is the width of the arrow.
{
"actStepSize": [ 1.1, 1.1 ],
"actionClip": [ -1, 1 ],
"actionValueFactor": 5.0,
"agentActs": [],
"agentCurrentAct": [ 0, 0 ],
"agentCurrentLoc": [ 2.5, 2.5 ],
"agentLocs": [
[ 2.5, 2.5 ]
],
"endPointMode": 1,
"endPointRadius": 1.0,
"flagActionClip": false,
"flagActionValue": true,
"isRandomCoordinating": true,
"isTerminated": false,
"mapFn": "RSE_13_1_GMEnv_Map.json",
"maxSteps": 100,
"nSteps": 0,
"name": "GridMapEnv_01",
"nondimensionalStep": true,
"nondimensionalStepRatio": 0.1,
"normalizedCoordinate": true,
"randomCoordinatingVariance": 0.2,
"totalValue": 0,
"visAgentRadius": 0.1,
"visForcePauseTime": 0.001,
"visIsForcePause": true,
"visPathArrowWidth": 0.1
}
Read an environment with map and interaction history.
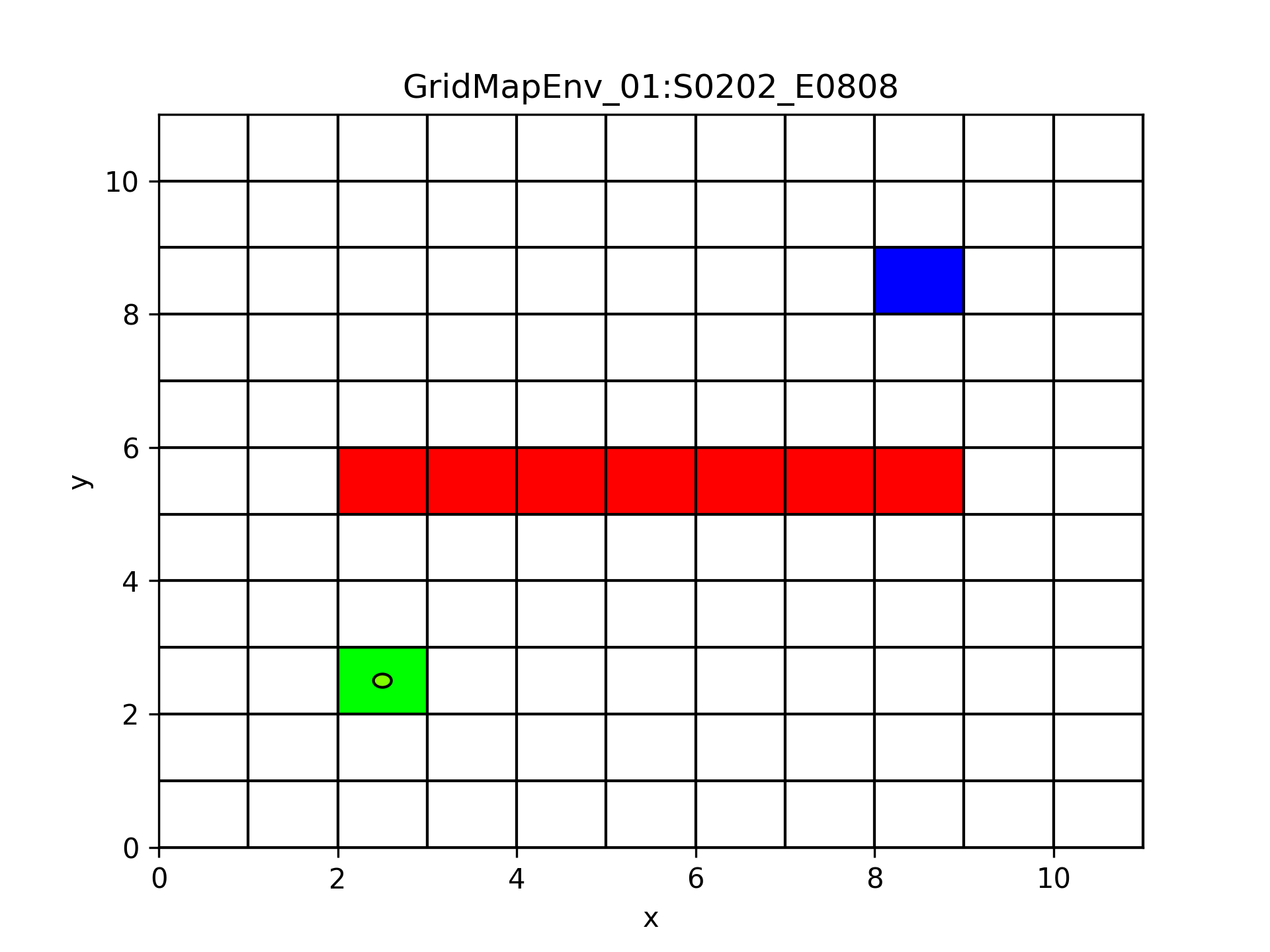
Here we have an actual state-action history produced from our reinforcement learning model. The history is saved in the environment JSON file.
{
"actStepSize": [ 1.1, 1.1 ],
"actionClip": [ -1, 1 ],
"actionValueFactor": 5.0,
"agentActs": [
[-0.6520129940236956, 0.8266539202963825],
[-0.35028478917287753, 0.5651496215539535],
[-0.38514930722046103, 0.7519560665214722],
[-0.04477470458665511, 0.7020456770772885],
[0.10703485167595206, 0.6370423544447013],
[0.20191812259693487, 0.6578672506690308],
[0.3247610830712133, 0.5483639290604652],
[0.5438775866229404, 0.46919911336868303],
[0.8343731226765141, 0.2785065468910668],
[0.757525377742676, 0.20724495498727524],
[0.6949142040109964, 0.14618178559790884],
[0.6118330455949978, 0.17402328568885395],
[0.7180226742487577, 0.0861312340746796],
[0.885514067842621, 0.03151112948817669],
[0.7841304101207704, -0.02654509564795049],
[0.27785945122093647, -0.08017478178554782],
[0.4745407889189419, -0.04929628746751291]
],
"agentCurrentAct": [ 0.4745407889189419, -0.04929628746751291 ],
"agentCurrentLoc": [ 8.284082991340563, 8.425860704818927 ],
"agentLocs": [
[ 2.5, 2.5 ],
[1.8479870059763044, 3.3266539202963825],
[1.4977022168034269, 3.891803541850336],
[1.1125529095829658, 4.643759608371808],
[1.0677782049963107, 5.345805285449097],
[1.1748130566722628, 5.982847639893798],
[1.3767311792691976, 6.640714890562829],
[1.701492262340411, 7.189078819623294],
[2.2453698489633513, 7.658277932991977],
[3.0797429716398654, 7.936784479883044],
[3.8372683493825415, 8.144029434870319],
[4.532182553393538, 8.290211220468228],
[5.144015598988536, 8.464234506157082],
[5.862038273237293, 8.550365740231761],
[6.747552341079914, 8.581876869719938],
[7.531682751200685, 8.555331774071988],
[7.809542202421621, 8.47515699228644],
[8.284082991340563, 8.425860704818927]
],
"endPointMode": 1,
"endPointRadius": 0.5,
"flagActionClip": false,
"flagActionValue": true,
"isRandomCoordinating": true,
"isTerminated": true,
"mapFn": "GMEnv_Traj_Map.json",
"maxSteps": 100,
"nSteps": 17,
"name": "GridMapEnv_02",
"nondimensionalStep": true,
"nondimensionalStepRatio": 0.1,
"normalizedCoordinate": true,
"randomCoordinatingVariance": 0.2,
"totalValue": 98.4,
"visAgentRadius": 0.1,
"visForcePauseTime": 0.5,
"visIsForcePause": true,
"visPathArrowWidth": 0.1
}
Map with state-atction history ↑
It is pretty straight forward to read and render this environment.
import GridMap
workingDir = "/path/to/the/env/JSON/file"
gme = GridMap.GridMapEnv( gridMap=None, workingDir=workingDir )
gme.load( workingDir, "ENV.json" )
# Do not call reset() after loading the environment unless you want to wipe out the history.
# gme.reset()
gme.render(flagSave=True)
Build an environment from scratch and interact.
In the following sample code, we build a map, and then we make the agent moving in the map.
In the grid map, the index is described in order of row-column and is zero-based. Index (1, 2) means the second row and the third column. The values for an index are always integers. A coordinate is expressed by (x, y), that is in the order of column-coordinate and row-coordinate. The values for a coordinate are real numbers.
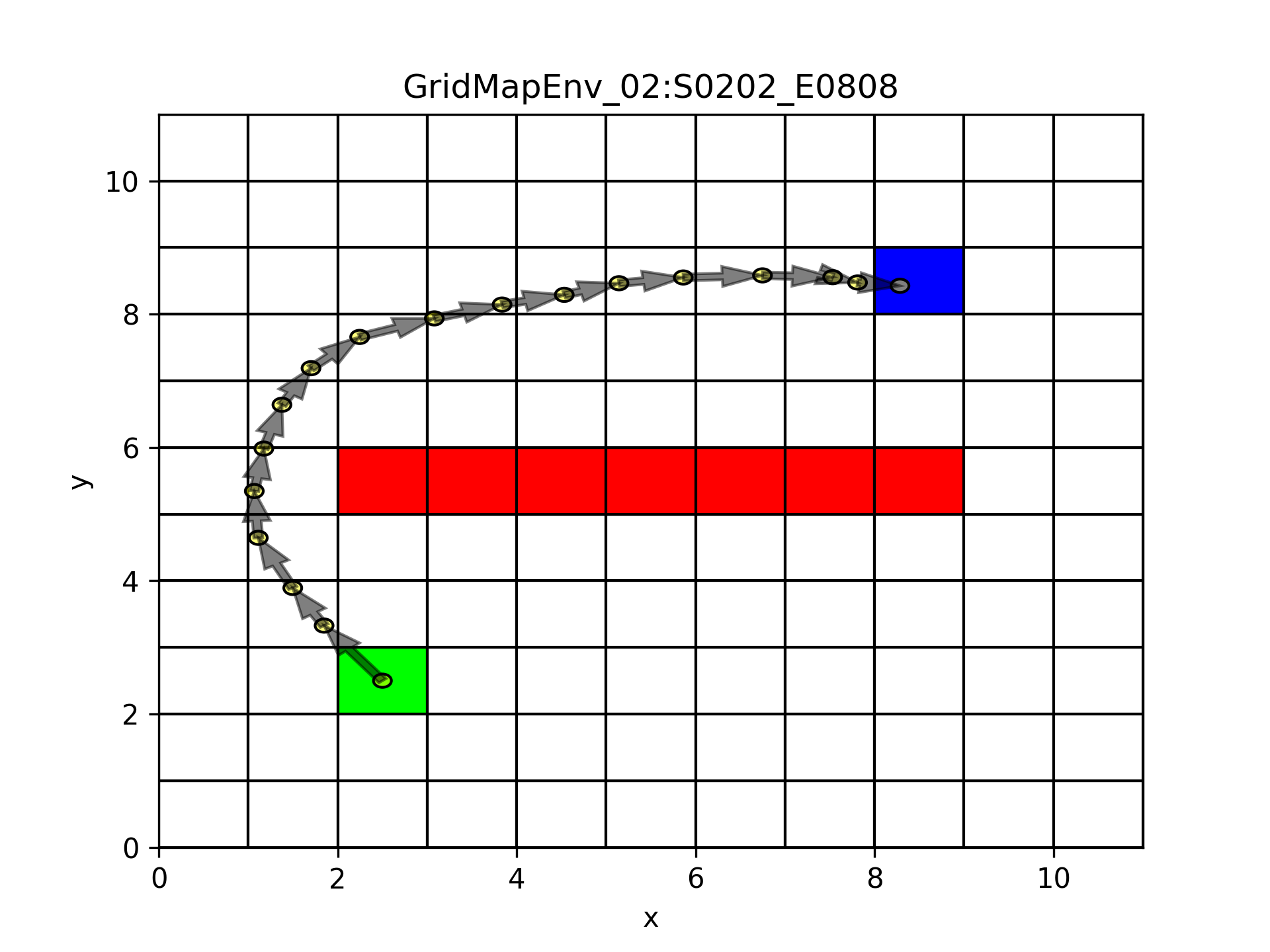
The map is 10x20 grids. We define various rewards/penalties for different blocks. The starting block is set to be at block index (0,0) and the ending block is all the way up to index (9, 19). Then we added a bunch of obstacles.
For this sample we are not using normalized coordinates or non-dimensional actions, this makes it easier to calculate the movement by hand. However, we could perform movements in terms of grid step sizes (the height and width of a grid cell). The agent starts at the center of the starting block (0.5, 0.5). Then we first move north to coordinate (0.5, 4.5). Next, the agent tries to move east with 11 grid steps. This makes the agent hit the vertical grid line of the obstacle. Then the agent moves away from the obstacle and makes another move to (15.5, 2). The agent tries a huge leap to the north with 100 grid steps and it stops by the northern boundary at (15.5, 10). The agent moves away from the boundary and then take its final move to the ending block. Here the last action shows that the map is working in continuous coordinate.
Under the settings of this environment, the agent only achieves -204 as its reward. (Without any restrictions on the step size, the optimum reward is 99 for this example.)
Build a map from scratch and interact ↑
import GridMap
gridMap = GridMap.GridMap2D(10, 20, outOfBoundValue=-200)
gridMap.set_value_normal_block(-1)
gridMap.set_value_starting_block(-1)
gridMap.set_value_ending_block(100)
gridMap.set_value_obstacle_block(-100)
gridMap.initialize()
# Overwrite blocks.
gridMap.set_starting_block((0, 0))
gridMap.set_ending_block((9, 19))
gridMap.add_obstacle((0, 10))
gridMap.add_obstacle((4, 10))
gridMap.add_obstacle((5, 0))
gridMap.add_obstacle((5, 9))
gridMap.add_obstacle((5, 10))
gridMap.add_obstacle((5, 11))
gridMap.add_obstacle((5, 19))
gridMap.add_obstacle((6, 10))
gridMap.add_obstacle((9, 10))
workingDir = "./WD_TestGridMapEnv"
self.gme = GridMap.GridMapEnv( gridMap=gridMap, workingDir=workingDir )
self.gme.reset()
# Get the actual grid step size
stepSizeX = self.gme.map.get_step_size()[GridMap.GridMap2D.I_X]
stepSizeY = self.gme.map.get_step_size()[GridMap.GridMap2D.I_Y]
totalVal = 0
# Move north with 4 grid steps.
action = GridMap.BlockCoorDelta( 0 * stepSizeX, 4 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( not flagTerm )
totalVal += val
# Move 11 gride steps east, stopped by the boundary at (10, 4.5)
action = GridMap.BlockCoorDelta( 11 * stepSizeX, 0 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( not flagTerm )
totalVal += val
# Move away from the obstacle by 1 grid step west and 1.5 grid step south.
action = GridMap.BlockCoorDelta( -1 * stepSizeX, -1.5 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( not flagTerm )
totalVal += val
# Move to (15, 2)
action = GridMap.BlockCoorDelta( 6.5 * stepSizeX, -1 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( not flagTerm )
totalVal += val
# Move 100 in north and stopped by the boundary.
action = GridMap.BlockCoorDelta( 0 * stepSizeX, 100 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( not flagTerm )
totalVal += val
# Back off from the boundary.
action = GridMap.BlockCoorDelta( 1 * stepSizeX, -0.8 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( not flagTerm )
totalVal += val
# Go directly to the ending block.
action = GridMap.BlockCoorDelta( 3 * stepSizeX, 0.6 * stepSizeY )
coor, val, flagTerm, _ = self.gme.step( action )
assert( flagTerm )
totalVal += val
self.gme.render(3, flagSave=True)
Ending block with radius mode.
As requested by the research, we develop a new mode of ending block. Previously, the ending block is a grid cell with a specific reward. An agent has to reach the inside of the ending block to trigger the termination or the episode. Now we could use a new mode called the “radius mode”.
In the radius mode, the user specifies a coordinate inside the ending block as the center ending point. Then the user defines a radius to effectively draw a circular region around the center ending point to be the ending region. To terminate the episode, the agent has to reach the inside of the circular region.
The radius mode is enabled by calling enable_ending_point_radius(). When calling this function, a value for the radius is required. It is not required that obstacles and out-of-boundary regions to not intersect with the circular region. Further, the distance between the center of the starting block and the center ending point is not controlled. The user could issue check_ending_point_radius() to see if the center of the starting block resides in the circular region of the ending block. Use disable_ending_point_radius() to disable.
The following figure shows a map with the ending block radius mode enabled. The ending block index is (6, 3) and the center ending point is (3.057034832009622, 6.5494725009552965). Note that the ending block index and center ending point coordinate are defined in the JSON file of the map, but the radius is set by the environment with the value of endPointRadius in the other JSON file. Also in the environment JSON file, endPointMode is 2 when the ending point radius mode is enabled, otherwise, it is 1.
Note that the random_ending_block() member function of GridMap2D always generate a random center ending point inside the ending block. set_ending_block() accepts an argument endPoint as a list or a BlockCoor object. The user could use this argument to specify the center ending point inside the ending block. The center ending point is not allowed to be outside the ending block. Doing this will raise an exception.
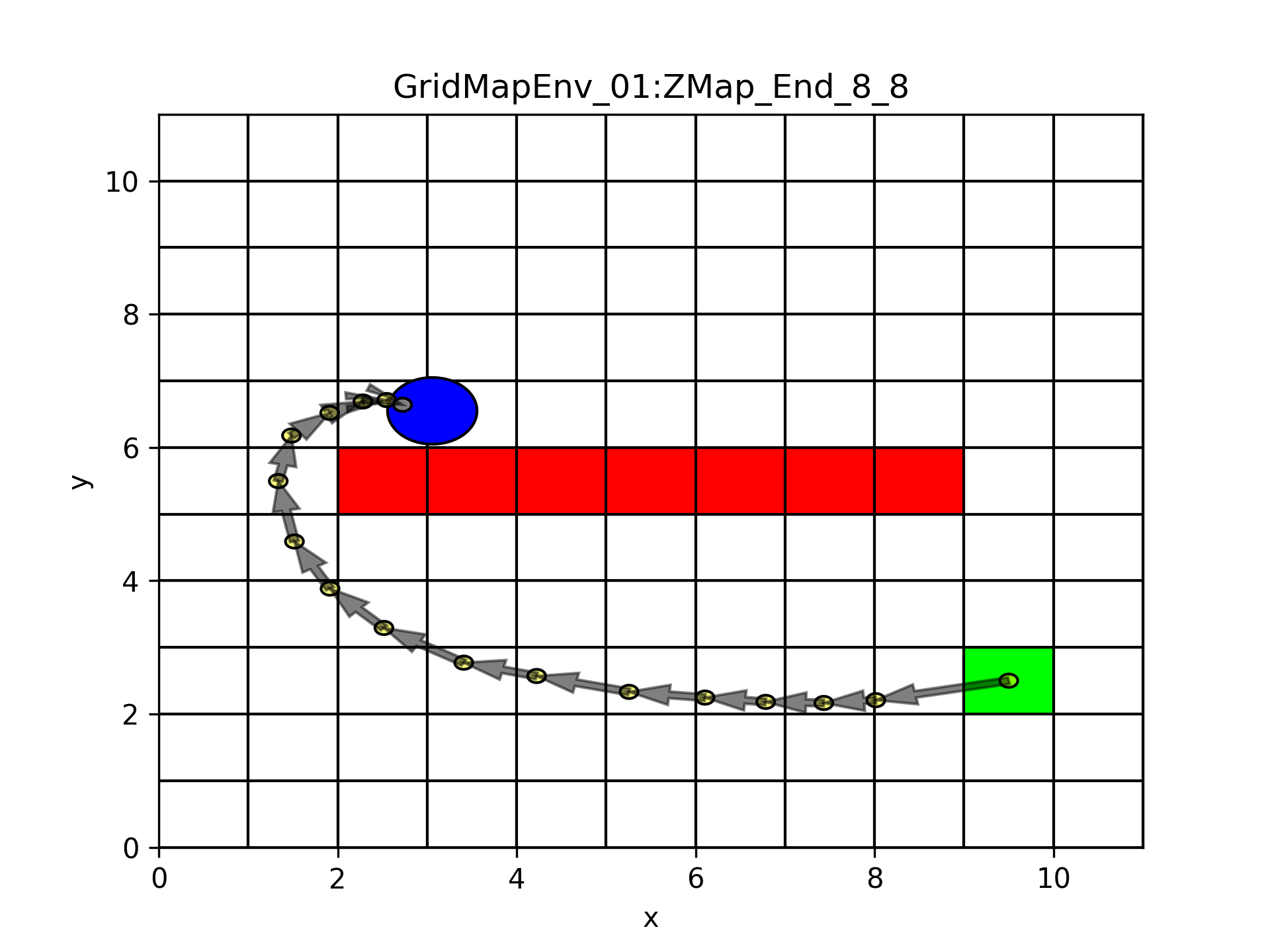
Ending block radius mode ↑